Next iteration of our Voice Assistant is here - Voice chapter 10
 Mike Hansen
Mike Hansen
Welcome to Voice chapter 10 🎉, a series where we share all the key developments in Open Voice. This chapter includes improvements across every element of Open Voice. Improvements that allow it to support more languages, be used on more hardware, make it easier to contribute to, all while making it faster and more reliable.
Help steer Open Voice
Before we get going, we just want to say that Voice Chapter 10 isn’t just a broadcast; it’s an invitation ✉️. Our public Voice project board lives on GitHub, and it shows what we’re fixing, currently building, and what we’ll work on next. Every card is open for comments, so please feel free to have a look and participate in the discussion.
👉 Project board: https://github.com/orgs/OHF-Voice/projects/2
ESPHome gains a voice
When we began designing and building the firmware for our open voice assistant hardware, the Home Assistant Voice Preview Edition, we had several specific features in mind:
- Run wake words on the device.
- Use a fully open-sourced media player platform that can decode music from high-quality sources.
- Wake words can be enabled and disabled on the fly; for example, “stop” is only activated when a long-running announcement is playing or when a timer is ringing.
- Mix voice assistant announcements on top of reduced volume (a.k.a. “ducked”) music.
These features needed to run within ESPHome, the software that powers the device. In the beginning, ESPHome could only do 1 and 2, but not even at the same time!
To include all these features, we initially built them as external components, allowing us to iterate fast (and of course break many things along the way). We always intended to bring these components into ESPHome, and the process of bringing them in is called upstreaming. This would allow anyone to easily build a voice assistant that includes all the features of Voice Preview Edition, and that’s what we’ve been working on since its launch last December.
 No device left behind!
No device left behind!
ESPHome version 2025.5.0 has all these components included! We didn’t just spend this time copying the code over, but we also worked hard to improve it by making it more generalizable, easier to configure, and much faster.
As an example of these speed improvements, the highest CPU load on the Voice Preview Edition happens when music is being mixed with a long announcement. In this situation, it is decoding two different FLAC audio streams while also running three microWakeWord models (a Voice Activity Detector, “Okay Nabu”, and “Stop”). With the original December firmware, this used 72% of the CPU 😅. With the new optimizations, which are all now available in ESPHome, the current Voice Preview Edition firmware only uses 35%❗ These improvements even allow the extremely resource-constrained ATOM Echo to support many of these features, including media playback and continuing conversations.
Make your own Voice Preview Edition
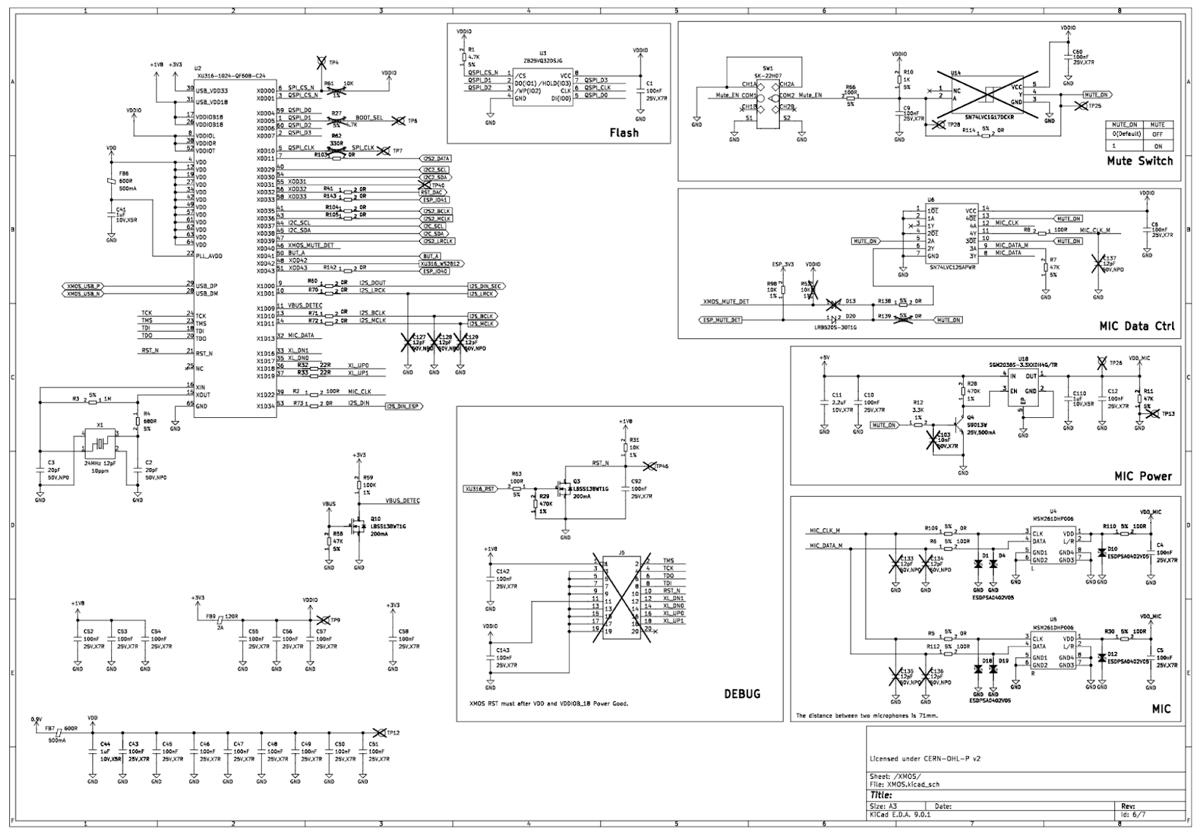 I'll just pretend I understand all this
I'll just pretend I understand all this
Speaking of voice hardware becoming more like Voice Preview Edition, why not use that class-leading hardware as the basis for your own creations? We’ve now got the KiCad project files, which include the electrical schematic and circuit board layout, along with other helpful documents available for download on GitHub. Combined with our open source firmware files, this will allow anyone to build on the work we’ve done and make the open voice assistant of their dreams. Bigger speaker, built-in presence sensor, a display featuring a smiling Nabu mascot — the options are nearly endless. Building Voice Preview Edition was always meant to bootstrap an entire ecosystem of voice hardware, and we’re already seeing some amazing creations with this open technology.
Now you’re speaking my language
Speech-to-Phrase gets more fluent
In case you missed it, we built our own locally run speech-to-text (STT) tool that can run fast even on hardware-constrained devices. Speech-to-Phrase works slightly differently from other STT tools, as it only accepts specific predetermined phrases, hence the name. We have been making large strides in making this the best option for local and private voice control in the home.
The sentence format for Speech-to-Phrase is getting an upgrade! Besides making it simpler for community members to contribute, it now allows for more thorough testing to ensure compatibility with existing Home Assistant commands.
We have also begun experimenting with more precise sentence generation, restricting sentences like “set the {light} to red” only to lights that support setting color. Another improvement is making Speech-to-Phrase more careful about combining names and articles in certain languages. For instance, in French, a device or entity that starts with a vowel or an “h” will have an “l” apostrophe at its beginning, such as l’humidificateur or l’entrée. Allowing Speech-to-Phrase to understand this avoids it guessing pronunciations for nonsensical combinations.
Speech-to-Phrase currently supports six languages, namely English, French, German, Dutch, Spanish, and Italian. We are now engaging with language leaders to add support for Russian, Czech, Catalan, Greek, Romanian, Portuguese, Polish, Hindi, Basque, Finnish, Mongolian, Slovenian, Swahili, Thai, and Turkish — this takes our language support to 21 languages 🥳!
These new models were originally trained by community members from the Coqui STT project (which is now defunct, but luckily their work was open source — another example of FOSS saving the day), and we are very grateful for the chance to use them! Performance and accuracy vary heavily by language, and we may need to train our own models based on feedback from our community.
Piper is growing in volume
Piper is another tool we built for local and private voice in the home, and it quickly turns text into natural-sounding speech. Piper is becoming one of the most comprehensive open source text-to-speech options available and has really been building momentum. Recently, we have added support for new languages and provided additional voices for existing ones, including,
- Dutch - Pim and Ronnie - new voices
- Portuguese (Brazilian) - Cadu and Jeff - new voices
- Persian/Farsi - Reza_ibrahim and Ganji - new language
- Welsh - Bu_tts - new voices
- Swedish - Lisa - new voices
- Malayalam - Arjun and Meera - new language
- Nepali - Chitwan - new voices
- Latvian - aivar- new voices
- Slovenian - artur - new voices
- Slovak - lili - new voices
- English - Sam (non-binary) and Reza_ibrahim - new voices
This brings Piper’s supported languages and dialects from 34 to now 39 🙌! This allows a nice majority of the world’s population (give or take 3 billion people) the ability to generate speech in their native tongue 😎!
Scoring language support
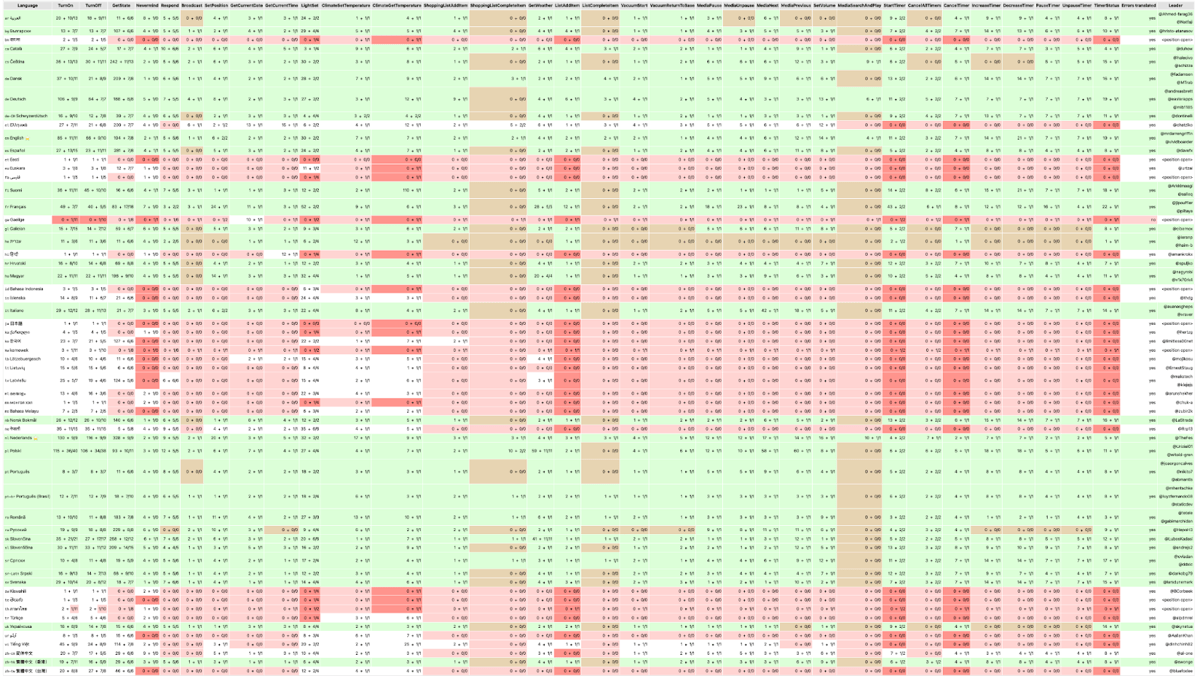 This is the score sheet for just intents... it can get complicated
This is the score sheet for just intents... it can get complicated
Home Assistant users, when starting their voice journey, typically ask one question first: “Is my language supported?” Due to how flexible voice assistants in Home Assistant are, this seemingly simple question is quite complicated to answer! At a high level, a voice assistant needs to convert your spoken audio into text (speech-to-text), figure out what you want it to do (intent recognition), and then respond back to you (text-to-speech). Each part of this pipeline can be mixed and matched, and intent recognition can even be augmented with a fallback to a large language model (LLM), which is great at untangling misunderstood words or complex queries.
Considering the whole pipeline, the question “Is my language supported?” becomes “How well does each part support my language?” For Home Assistant Cloud, which uses Microsoft Azure for voice services, we can be confident that all supported languages work well.
Local options like Whisper (speech-to-text) and, to a lesser extent, Piper (text-to-speech), may technically support a language but perform poorly in practice or within the limits of a user’s hardware. Whisper, for example, has models with different sizes that require more powerful hardware to run as they get larger. A language like French may work well enough with the largest Whisper model (which requires a GPU), but is unusable on a Raspberry Pi or even an N100-class PC.
Our own Speech-to-Phrase system supports French well and runs well on a Raspberry Pi 4 or Home Assistant Green. The trade-off is that only a limited set of pre-defined voice commands are supported, so you can’t use an LLM as a fallback (because unexpected commands can’t be converted into text for the LLM to process).
Finally, of course, not everyone wants to (or can) be reliant on the cloud, and they need a fully local voice assistant. This means that language support depends as much on the user’s preferences as their hardware and the available voice services. For these reasons, we have split out language support into three categories based on specific combinations of services:
- Cloud - Home Assistant Cloud
- Focused Local - Speech-to-Phrase and Piper
- Full Local - Whisper and Piper
Each category is given a score from 0 to 3, with 0 meaning it is unsupported and 3 meaning it is fully supported. Users who choose Home Assistant Cloud can look at the Cloud score to determine the level of language support. For users wanting a local voice assistant, they will need to decide between Focused Local (limited commands for low-powered hardware) and Fully Local (open-ended commands for high-powered hardware). Importantly, these scores take into account the availability of voice commands translated by our language leaders. A language’s score in every category will be lowered if it has minimal coverage of useful voice commands.
With these language scores, we hope users will be able to make informed decisions when starting on their voice journeys in Home Assistant. They’re currently featured in our voice setup wizard in Home Assistant, and on our language support page.
What’s in a name
Voice commands in Home Assistant trigger intents, which are flexible actions that use names instead of IDs. Intents handle things like turning devices on or off, or adjusting the color of lights. Until now, sentence translations focused on whether a language supported an intent (like turning devices on/off) but didn’t clearly show whether the command supported device names, areas names, or both. This can change from language to language, which made gaps hard to spot. We’re switching to a new format that highlights these combinations, making it easier for contributors to see what names are supported, which should make for simpler translations.
Continued conversation updates
Since the last voice chapter, the voice team has worked on making Assist more conversational for LLM-based agents. We started with LLM-based agents because it was simpler to iterate on. If the LLM returns with a question, we will detect that and keep the conversation going, without the need for you to say “Ok Nabu” again.
On top of that, you can now initiate a conversation with a new action called start_conversation directly from an automation, or a dashboard. This provides the full spectrum of conversation to LLM-based agents.
Here is a quick demonstration of two features working hand-in-hand:
Media Search and Play intent
What’s great about Home Assistant and open source is that sometimes the best ideas come from other projects in the community. Early on, many people were interested in driving Music Assistant with voice, but central pieces were missing on Home Assistant, such as the ability to search a media library.
We worked hard on bringing this functionality to the core experience of Home Assistant and created a new intent, the Search and Play intent. You can now speak to your voice assistant and ask it to play music in any room in your home.
The intent can be used by an LLM-based conversation agent, but we also have sentences that work without any LLM magic. You can find the English sentences here. As it’s a new feature, support may vary based on your language, and please be patient while our amazing language leaders make these translations.
Future work - Assist will have something to say
Talking to your home should feel as natural as chatting with a friend across the kitchen counter. Large-language models (LLMs) already prove how smooth that back-and-forth can be, now we want every Home Assistant installation to enjoy the same experience. We’re therefore zeroing in on three key use-cases for the default conversation agent, which include critical confirmations, follow-ups, and custom conversations. Just note these are still at the early stages of development and it may be some time before you see some of these features.
Critical confirmations
Some actions are too important to execute without a quick double-check. Unlocking the front door, closing shutters, or running a “leaving home” script. We want you to be able to mark those entities as protected. Whenever you speak a command that touches one of those entities, Assist will ask for verbal confirmation before acting:
Ok Nabu, unlock the front door
Are you sure?
Yes
Unlocked
Because every household is different, we are thinking about managing these confirmations per entity and making them fully user-configurable.
Follow-up on missing parameters
Sometimes Assist grasps what you want, but needs more detail to carry it out. Instead of failing, we want Assist to ask for the missing piece proactively. Here is an example to illustrate.
Ok Nabu, set a timer
For how long?
15 minutes
Timer started
For now, we are still assessing the relevant sentences for that use case. We’re implementing follow-ups with timers, though finding more is not currently our top priority. We are, however, open to suggestions.
Custom conversations
As with any other part of Home Assistant, we want the conversation aspect of Assist to be personalized. Simple voice transactions can already be created with our automation engine using the conversation trigger and the set_conversation_response action.
We want to bring the same level of customization to conversations, allowing you to create fully local, predefined conversations to be triggered whenever you need them, such as when you enter a room, start your bedtime routine, etc.
We are focusing first on making custom conversations possible, so that you can show us what you are building with this new powerful tool. We will then tackle the critical confirmations use case, and finally, the follow-ups when parameters are missing.
Let’s keep moving Open Voice forward
Only a couple of years ago, voice control was the domain of data-hungry corporations, and basically none of this open technology existed. Now, as a community, we’ve built all the parts needed to have a highly functional voice assistant, which is completely open and free for anyone to use (or even build on top of).
Every chapter, we make steady progress, which is only possible with your support. Whether from those who fund its development by supporting the Open Home Foundation (by subscribing to Home Assistant Cloud, and buying official Home Assistant hardware) or those who contribute their time to improving it. As always, we want to support every language possible, and if you don’t see your native tongue on our supported list, please consider contributing to this project.